
DynamoDB 주요기능 - Stream
테이블에 조작(추가/삭제/갱신)이 가해질 때 발생하는 비동기적 알림 데이터.
AWS 서비스에서 트리거로써 활용될 수 있다.
어떤 조작이 가해졌는지,
OLD_VALUE와 UPDATED_VALUE에 대한 정보도 들어있다.

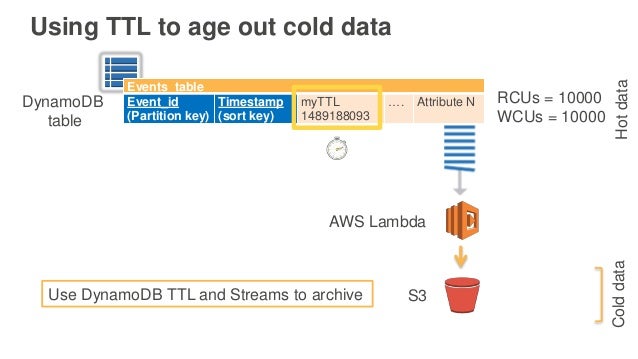
DynamoDB 주요기능 - TTL
데이터에 수명을 달아주는 기능.
각 아이템 항목마다 MyTTL 속성이 추가되며, 해당 시각이 자나가면 테이블에서 삭제된다.
단, 데이터가 생성되고 몇 분 이후에 사라지는 개념이 아니라,
데이터가 생성될 때 애초에 데이터가 사라지는 시각을 정하는 방식이다.
(2020-02-13 추가됨)
TTL이 초과되어 데이터가 삭제되는 경우에는 WCUs도 사용되지 않고 요금도 발생하지 않는다.
수작업으로 데이터를 삭제하지 않아도 되고, 요금도 싸게 먹힌다.
(2020-02-13 추가됨)
TTL이 지난 데이터가 삭제되기까지 딜레이가 있을 수 있다.
즉, 데이터를 조회했을 때 TTL이 지난 데이터가 포함될 수 있다는 것이다.
이러한 불상사를 막으려면, 만료된 항목을 필터링하는 조건식을 포함하여 조회해야 한다.
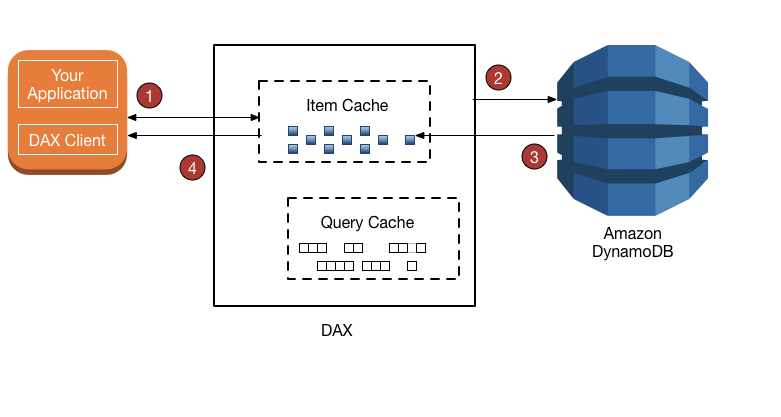
DynamoDB 주요기능 - DAX (DynamoDB Accelerator)
인 메모리 캐싱 서비스.
이 기능을 활성화하면 자동적으로 캐싱이 제공된다.
시간당으로 추가적인 온디멘드 요금이 청구되므로 주의.
(2020-02-13 추가됨)
아직 서울리전에서는 지원하지 않는다.
캐싱이 꼭 필요하다면 일본리전으로 옮겨서 사용하거나,
반드시 서울리전에서 서비스해야 한다면 DAX를 제외한 다른 캐싱전략을 사용해야 한다.
DynamoDB 주요기능 - Transaction
원자성 연산의 단위.
NoSQL에서는 트랜잭션 미지원이 대표적인 단점이였지만,
DynamoDB에서는 이 문제를 해결했다고 셀링 포인트로 홍보하고 있다.

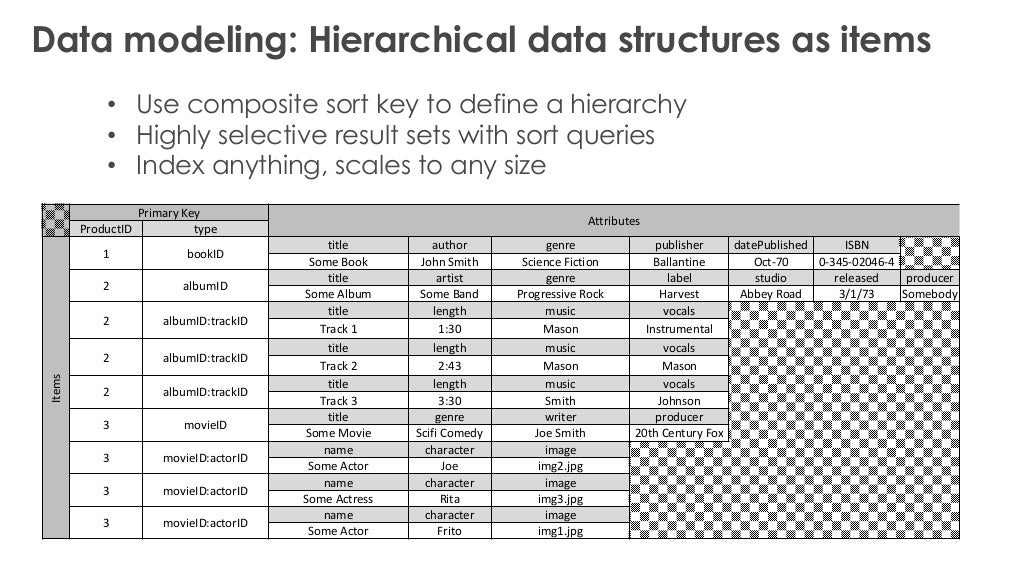
데이터 모델링 기본
타입을 결정하는 속성을 두고,
타입에 따라 추가속성이 결정되도록 계층적 구조로 관리.
(2020-02-13 추가됨)
TYPE === 1 (또는 book_ID !== null)이라면 BOOK 데이터이고,
book_title, total_page, ... 와 같은 속성이 있을것이고.
TYPE === 2 (또는 video_ID !== null)이라면 VIDEO 데이터이고,
video_title, total_time, ... 와 같은 속성이 있을것이라는 이야기이다.
모델링 예제 (1) : 데이팅 어플
요구사항
> 내가 LIKE한 사람을 알 수 있어야 함.
> 누가 나를 LIKE했는지 알 수 있어야 함.
> LIKE는 90일이 지나면 만료됨.
> 1시간마다 매치가 된 사람을 처리해야 함.
> LIKE 정보와 MATCH 정보는 각각의 테이블에 저장되어야 함.
LIKE 디자인
> 자신의 아이디를 Hash Key로 지정.
> 내가 좋아한 사람을 Range Key로 지정.
> 누가 자신을 좋아했는지 알 수 있도록, GSI로 역방향 인덱스를 구성.
> 90일이 지나면 만료되도록 TTL 서비스를 활성화한다.

MATCH 디자인
> 매치 이벤트에 고유 아이디를 부여하고 Hash Key로 설정.
> 좌측, 우측 유저의 관점으로 각각 GSI를 생성.

비효율적인 MATCH 감지 알고리즘
1. 매 시간마다 새롭게 생성된 LIKE를 가져온다.
2. 각 LIKE에 대해, 다른 사람도 나를 LIKE하는지 검사한다.
3. 매칭되었다면 MATCH 테이블에 저장한다.
> 특정 시간에 한꺼번에 LIKE 테이블에 읽기 접근이 발생하므로,
> 쓰로틀이 발생할 확률이 급증함.

개선된 MATCH 알고리즘
1. LIKE가 발생하는 즉시, 다른 사람도 날 LIKE하는지 검사한다.
2. 매칭되었다면 MATH 테이블에 저장한다.
> LIKE 테이블에 Stream를 활성화하여 Match를 발생시키는 API를 트리거한다.
> 인 메모리 캐싱 기능인 DAX을 활성화하면 더욱 효과적이다.

모델링 예제 (2) : IoT
요구사항
> 각 사용자는 여러개의 센서를 가지고 있음.
> 센서에서 취득된 데이터가 DB에 저장됨.
> 언제 데이터가 취득되었는지 (시계열 순서)가 중요함.
> 90일이 지나면 S3 스토리지로 이동할 것.
스키마 디자인
> 시계열 정렬을 할 수 있도록 Timestamp를 Range Key로 설정함.
> 90일이 지나면 만료되도록 TTL 기능을 활성화한다.
> TTL이 지나서 삭제된 데이터를 감지할 수 있도록 Stream 기능을 활성화 한다.
> Stream에 삭제 이벤트로 전달된 데이터는 S3 버킷에 집어넣는다.

성능 이슈
> 디바이스 ID가 파티션키이므로,
> 같은 디바이스에서 수집된 데이터는 같은 파티션에 존재한다.
> 다른 얘들보다 데이터를 많이 수집하는 센서가 문제인데,
> Heavy하게 데이터를 수집하는 센서의 파티션은 쓰로틀링이 발생할 수 있다.

다이나믹 샤딩 (Dynamic Sharding)
> 동적으로 데이터가 저장될 파티션을 결정하는 기법.
> 분산 저장과 가장 의미가 비슷할 듯.
> 여기서는 랜덤함수로 저장될 파티션을 지정한다. (라운드 로빈도 가능!)
> 원래 Data 테이블의 파티션키에 ShardId를 덧붙인다.


다이나믹 샤딩수준 결정
> 각 기기마다 다이나믹 샤딩 수준을 별개로 결정하는 것이 좋다.
> Cold Device에서는 샤딩 수준이 높아도 별 소용이 없기 때문이다.
> 각 디바이스의 다이나믹 샤딩수준을 결정하는 SHARD 테이블을 생성한다.
> 만약 이래도 쓰로틀이 발생한다면, 해당 기기의 ShardCount를 더 크게 잡는다.

최종 설계도

'# Tech > DynamoDB' 카테고리의 다른 글
| DynamoDB + GUI 로컬 개발환경 세팅하기 (0) | 2019.12.09 |
|---|---|
| DynamoDB 깊게 입문하기 (1) - DynamoDB Deep Dive (1) (7) | 2019.11.17 |

