
NoSQL
장점
유연한 수평확장
수평확장 (Scale-Out)이 쉽고 유연하다. RDB에서 수평확장을 하려면 머리가 꽤 아플것이다.
빠른 레이턴시
대규모 서비스도 저렴하게 운영이 가능하며 응답속도도 빠르다.
유연한 스키마
RDB보다 유연한 스키마 설계가 가능하다.
단점
조인이 불가능하므로 복잡한 데이터 로직이 포함되어 있으면 성능이 급감한다. 데이터 모델들이 혼자서도 운용될 수 있도록 독립적으로 설계 해야한다.
DynamoDB
장점
더 빠른 레이턴시
어떤 규모의 서비스에서도 빠른 응답이 가능하다. 구체적으로는 10ms 미만의 레이턴시라고 자랑하고 있는데 미션 크리티컬한 시스템에서도 사용할 수 있다고 설명한다.
완전 관리 시스템
완전 관리형이므로 개발자는 데이터 조작 및 스키마 정의에만 신경쓰면 된다. 스토리지가 꽉 차면 알아서 늘어나고 트래픽이 급증하면 자신의 성능을 일부 조절할 수 있다. 백업도 알아서 하기 때문에 개발자는 완전 편하다!
전용 캐시 솔루션
추가적인 비용을 내고 인 메모리 캐시 솔루션인 DAX(DynamoDB Accelerator)를 사용할 수 있다. DAX를 사용했을 때는 1ms 미만의 레이턴시의 응답속도를 자랑한다고 소개되어 있다. 그러나 2020-01-21 기준으로 서울에서 DAX를 지원하지 않는다.
원자성 트랜잭션 지원
NoSQL의 고질적인 단점이였던 원자성 트랜잭션을 지원한다.
나름 저렴한 유지비
나름 유지비가 저렴하다. 사용한 만큼만 지불하는 온디멘드와 사용할 만큼 미리 결제하는 프로비저닝이 있으므로 자신에게 적합한 과금유형을 선택하면 더 절약할 수 있다. 무료 사용량도 넉넉하여 왠만한 서비스는 프리티어로 커버할 수 있다.
단점
고질적인 NoSQL의 단점
조인을 지원하지 않는다는 등 왠만한 NoSQL의 단점을 그대로 물려받는다. 물론 조인은 적절한 모델링으로 해결할 수 있지만 알아둬서 나쁠건 없다.
진입장벽이 높음
어느 DB에서나 마찬가지겠지만 내부 아키텍쳐를 모른다면 최적의 성능을 보장할 수 없다. 그러나 특히 DynamoDB는 그 차이가 꽤 크다고 한다.
장단점 3줄 요약
왠만한 관리는 알아서 해주므로 그 시간에 국밥 한그릇을 더 먹을 수 있지만 내부 아키텍쳐를 모른 채 사용하면 화를 입을 가능성이 매우 크다. 반드시 NoSQL의 단점과 DynamoDB의 내부 아키텍쳐를 이해하고 사용해야 한다.
DynamoDB를 도입한 기업들
기본 아키텍쳐
테이블
테이블이란 여러개의 아이템을 저장할 수 있는 공간이다. 테이블이 커지면 파티션키를 기준으로 하여 자동적으로 여러개의 파티션으로 나뉘어 관리된다.
테이블을 생성할 때는 기본키(Primary Key)를 반드시 지정해야 하는데 이것을 통해 무결성을 보장하므로 기본키가 겹치거나 누락되면 안된다. 해시키(Hash Key, Partition Key)와 정렬키(Sort Key, Range Key)의 유무에 따라 아래와 같이 구분된다.
단순 기본키: Partition Key복합 기본키: Partition Key + Sort Key
파티션 키는 해시 속성이기 때문에 Hash Key라고도 불리며같다 또는 같지않다의 연산만 가능하다.
정렬키는 범위 속성이기 때문에 Range Key라고도 불리며비교대소 또는 ~으로 시작되는 형태의 연산도 가능하다.

데이터 타입
기본적인 원시 자료형은 3가지이다.
- S (String)
- N (Number)
- B (Binary)
원시 자료형에 Set이 붙으면 집합으로 변한다.
겉보기는 배열같지만 실제로는 집합이기 어떤 값이 2번이상 나올 수 없다.
- SS (String Set)
- NS (Number Set)
- BS (Binary Set)
나머지 기타 자료형은 다음과 같다.
- BOOL
- NULL
- L (List)
- M (Map)
아이템
저장될 데이터 값을 의미하며, 전통적인 RDB에서는 로우 또는 튜플에 대응된다.
아이템의 각 속성은 빈 문자열이나 undefined를 허용하지 않기 때문에,
어플리케이션 로직에서 이러한 체크를 철저히 해야된다.
NoSQL이므로 기본적으로 JSON 방식으로 표현되는데,
DynamoDB에서 사용하는 특별한 표기법이 존재한다.
{
Artist: {
S: "ARTIST_NAME" //! S는 String 데이터 타입을 의미한다. 빈 문자열이나 undefined는 허용하지 않는다.
},
SongTitle: {
S: "SONG_TITLE"
}
};인덱스
인덱스는 쿼리 검색에 도움을 주어 쿼리 성능을 향상시키는 도구이다. Primary Index는 기본키를 사용하여 자동으로 생성되지만 추가적인 성능 향상을 위해 Secondary Index를 추가할 수 있다. Secondary Index의 구조도 Primary Index의 구조와 같다.
- 단순 보조 인덱스 기본키 : Hash Key
- 복합 보조 인덱스 기본키 : Hash Key + Range Key
보조 인덱스에 사용된 파티션 키에 따라 보조 인덱스의 종류가 결정된다.
Primary Partition Key와 같음 : Global Secondary Index (GSI)Primary Partition Key와 다름 : Local Secondary Index (LSI)
(2020-01-02 수정)
- 파티션키와 정렬키 둘 다 다름 : Global Secondary Index (GSI)
- 파티션키는 같지만 정렬키가 다름 : Local Secondary Index (LSI)
위에서 테이블은 여러개의 파티션으로 관리될 수 있다고 설명했다.
보조 인덱스의 파티션 키가 주 인덱스의 파티션키와 다르면
보조 인덱스의 어떤 파티션 키 값이 모든 파티션에 접근할 수 있다는 의미에서 Global 이다.
보조 인덱스의 파티션 키가 주 인덱스의 파티션키와 같으면
보조 인덱스의 어떤 파티션 키 값이 특정 파티션만 접근할 수 있다는 의미에서 Local 이다.
보조 인덱스는 키가 아닌 일반속성도 포함할 수 있는데,
이러한 키가 아닌 일반속성을 프로젝션이라고 한다.
프로젝션이 늘면 당연히 인덱스의 크기도 늘어난다.
프로젝션의 유형은 다음과 같다.
KEYS_ONLY: 키만 있고 프로젝션 없음.INCLUDE: 일부 프로젝션만 포함.ALL: 모든 속성이 프로젝션되어 있음.
GSI는 각 테이블당 최대 20개LSI는 각 테이블당 최대 5개이다.

심화 아키텍쳐
용량유닛
용량유닛이란?
용량유닛(Capacity Units)는 1초당 읽거나 쓸 수 있는 데이터 단위를 지칭하며 얼마나 데이터베이스를 혹사시켰는지에 대한 지표이고 과금량의 지표로도 사용된다. 읽기 용량유닛(RCUs)과 쓰기 용량유닛(WCUs)은 각각 독립적으로 측정된다.
용량유닛을 설정할 수 있는 항목은 다음과 같다.
- GSI
- 테이블 (LSI는 테이블의 용량유닛을 사용함)
위의 리스트가 의미하는 것은 GSI가 소비하는 용량유닛은 테이블에 설정된 용량유닛과는 전혀 관계가 없다는 뜻이다. GSI에 설정된 용량유닛을 알기 위해서는 DescribeTable를 사용해야 한다.
프리티어
모든 테이블의 각 용량유닛을 더하고 시간당 RCUs 25, 시간당 WCUs 25을 넘지 않는 선에서 프리티어로 제공된다. 초과 사용분에 대해서 비용이 청구되며 최대 CUs를 설정하지 않았을 경우, 다다음 절에서 소개할 버스트(Burst)가 발생했을 때 많은 비용이 청구될 수 있다. 최대 CUs를 까먹지 말고 설정하자. 기본값은 40000이다.
과금량 계산
먼저 필터 조건절에 의해 걸러지기 전의 모든 아이템을 KB 단위로 환산된 뒤 소수점 이하를 올림하고 용량단위의 배수로 맞춰서 다시 올림한다. 1 Byte만 사용해도 용량단위의 배수로 맞춰서 올림된다는 뜻이다. 찔끔찔끔 여러번 가져오는 설계는 엄청난 과금을 발생시키는 주 원인이다.
각각의 용량단위는 다음과 같다. (1CU로 읽거나 쓸 수 있는 데이터의 량)
WCUs: 1KBRCUs: 4KB, Strictly Consistent ReadRCUs: 8KB, Eventually Consistent Read
그리고 어떤 API를 사용했는지에 따라 용량유닛 계산법이 달라진다.
단일아이템 조회 / 쓰기 : 해당 아이템의 용량을 단위배수로 올림.배치아이템 조회 / 쓰기 : 각 아이템을 용량을 단위배수로 올림한 뒤에 합산.쿼리조회 : 모든 아이템의 용량을 합산하고 단위배수로 올림.
(2020-02-04 추가)
배치 아이템 조회보다 쿼리 조회가 용량단위면에서 훨씬 경제적이지만,
쿼리는 단일 테이블 연산이고 배치는 다중 테이블 연산이다.
즉, 쿼리는 하나의 테이블만 조회할 수 있다는 한계가 있다.
GSI, 테이블 사이의 관계
(2020-05-20 추가)
둘 중 하나라도 수정된다면 반대편에게도 영향이 간다. 그러나 GSI와 테이블은 서로 다른영역에서 용량유닛을 사용하고 있기 때문에 쓰로틀이 발생할 가능성이 존재하게 된다.
테이블에서는 데이터를 수정시킬 용량유닛이 넉넉한데 GSI에서는 여유가 없다면? 어느 한쪽에서는 데이터 수정이 미뤄질것임이 분명하다. 그러나 수정된 데이터는 테이블과 GSI 모두에게 기록되어야 하기 때문에 반대편에 여유가 생길때까지 수정은 미뤄진다.
이러한 잠재적 문제를 예방하기 위해서 GSI의 용량유닛을 테이블보다 더 높게 설정할것을 권고하고 있다.
보조 인덱스 종류별 차이점
생성 가능한 테이블
GSI: 제한 없음.LSI: 복합 키본키를 갖는 테이블에만 생성가능.
인덱스의 키 속성
GSI: 제한 없음.LSI: 파티션키가테이블의 파티션키와 같아야 함.
인덱스 용량 제한
GSI: 제한 없음.LSI: 인덱스의 크기가10GB를 넘으면 안됨.
지원하는 읽기 일관성
GSI: Eventually ConsistentLSI: Eventually Consistent, Strictly Consistent
프로젝션되지 않은 속성 사용
GSI: 불가능. 에러발생.LSI: 쌉가능. 프로젝션되지 않아도 테이블에서 읽어옴.
생성/삭제 가능 타이밍
GSI: 언제든지 생성/삭제 가능LSI: 테이블이 생성될 때만 정의가능, 삭제 불가능.
용량유닛 공유
GSI: GSI가 공유하는 용량유닛에서 사용.LSI: 테이블에서 용량유닛 사용.
읽기 일관성
DynamoDB는 다음과 같은 읽기 일관성 모델을 지원한다.
- Eventually Consistent Read
- Strongly (Strictly) Consistent Read
Eventually Consistent Read는 Near Time이다.
비교적 최신의 값을 가져오지만 가장 최신은 아닐 수 있다.
쓰기 연산이 테이블에 제대로 반영되려면 약 1초가 걸리기 때문이다.
반면에 Strongly (Strictly) Consistent Read는 Real Time이다.
반드시 최신의 값을 가져오지만 2배 더 비싸다.
핫 파티션
해시키을 기준으로 파티션이 나눠진다는 것을 상기해보자.
특정 해시키가 인기가 많다면 해당 해시키가 저장된 파티션에 부하가 집중된다.
이렇게 부하가 집중된 파티션을 핫 파티션이라고 부르며 읽기/쓰기 성능이 급격하게 떨어진다.
아래의 사진은 핫 파티션이 발생했을 때의 모니터링 사진이다.
하나의 파티션은 일하느라 바쁜데, 다른 파티션은 여유로운지 파란색으로 가득차있다.
가뜩이나 인기있는 데이터인데 핫 파티션까지 발생했으니 엄청난 성능하락이 우려된다.
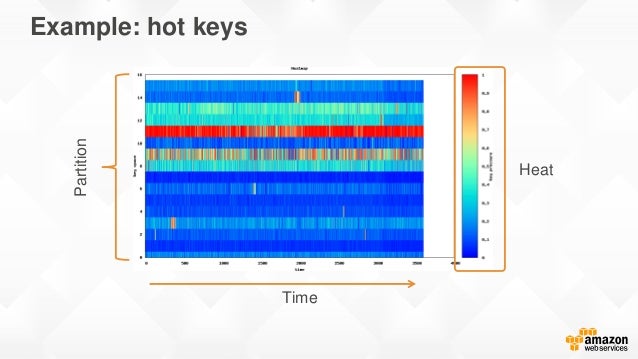
최대한 해시키 값을 골고루 탐색하도록 해야 파티션 부하가 분산되므로 핫 파티션을 피할 수 있다. 물론 개발자가 해시키 값을 골고루 탐색하도록 강제할 수 없기에 설계 단계부터 고려해야하는 사항이며 데이터를 균형있게 분산시켜줄 데이터를 해시키로 골라야 한다.
아래는 데이터를 균형있게 분포시켰을 때의 상황이다. 윗 사진에서 한 파티션에 몰려있었던 인기 데이터들이 모든 파티션에 골고루 퍼졌기 때문에 스트레스가 수직 형태로 나타났음을 볼 수 있다.
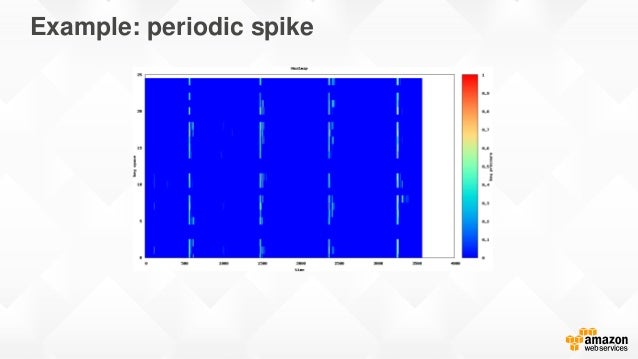
하지만 골고루 분산시켜줄 데이터가 없다면? 이러한 경우에 대한 해결책은 다음절인 샤딩에서 설명한다.
샤딩
(2020-05-20 추가됨)
해시키에 접미사를 붙여서 파티션을 분산시키는 설계를 샤딩이라고 부른다. 원래 해시키에 [0...N) 사이의 난수를 붙여넣으면 같은 해시키라도 서로다른 난수를 가지게되므로 서로다른 파티션에 저장되도록 노리는 것이다. 이러한 샤딩 전략은 크게 2가지로 나뉜다.
- 임의의 샤딩
- 계산된 샤딩
임의의 샤딩 (난수 샤딩)
위에서 예시로 설명한 샤딩이 바로 이것이며 [0...N)사이의 난수를 하나 골라 붙여넣는 방식이다. N이 크면 클수록 파티션 분산이 더욱 효과적으로 이루어진다. 그런데 무언가 놓치고 있는게 있다. 🤔 특정 데이터를 조회하려면 어떻게 해야 할까? 당연히 어느 난수를 가졌는지 모르기때문에 [0...N)을 모두 붙여서 쿼리를 날린뒤에 병합해야 한다.
계산된 샤딩 (해시 샤딩)
난수 샤딩의 이러한 한계점을 극복하기 위해 해시를 사용하는 샤딩을 권하고 있다. 일부 데이터를 해싱한 뒤에 그 결과를 해시키의 접미사로 사용하면 파티션 분산도 효과적으로 이루어지고 어떤 접미사를 사용했나?도 쉽게 알수있게 된다.
다음과 같은 테이블을 생각해보자.
카드회사 (S) : 삼성카드
고객번호 (N) : 54321카드회사를 해시키로 사용하면 같은 카드회사를 가진 항목들이 같은 파티션에 저장되게 될 것이다. 하지만 고객번호를 해싱해서 접미사로 붙이면? 단순하게 모듈러 100연산을 사용해서 삼성카드-21를 해시키로 사용해도 파티션 분산을 쉽게 달성할 수 있다.
이제 고객번호가 54321인 고객의 데이터를 찾으려면? 반대로 짚어나가면 된다. 고객번호인 54321에서 접미사인 21을 얻을 수 있고 카드회사인 삼성카드에 붙여넣으면 샤딩된 해시키인 삼성카드-21을 얻을 수 있다.
버스트
순간적으로 엄청나게 많은 요청이 들어오는 것을 버스트(Burst)라고 한다. DynamoDB는 파티션마다 최근 300초 동안 사용되지 않은 용량유닛을 저축한다. 그리고 버스트가 발생했다면 열심히 모아놨던 용량유닛을 활용하여 대처한다.

그러나 저축해놨던 용량유닛을 사용해도 부족한 경우 사용자가 설정한 최대 CUs까지 끌어올려서 처리를 시도한다. 증량된 용량유닛때문에 프리티어 한계를 넘었다면 증량분에 대한 요금이 부과되므로 주의하자. 이렇게 증랴된 용량유닛은 버스트가 잠잠해지면 서서히 최저 CUs로 낮춰진다.
하지만 영혼까지 끌어모았는데도 버스트를 대처할 수 없다면 다음절에서 소개할 쓰로틀이 발생한다.
쓰로틀
요청량이 너무 많다면 작업들을 전부 수용할 수 없기 때문에 일부 작업을 미루는 현상이 발생한다. 이렇게 데이터 처리가 미뤄진 것을 쓰로틀(Throttle)이라고 하며 정확히는 어떤 읽기/쓰기 작업이 중단되는 것이라고 말한다.
버스트가 발생했는데 사용할 수 있는 용량유닛도 없다면? 용량유닛에 여유가 생길때 까지 어떤 요청은 suspend되는 것이다. 아래 그림을 살펴보면 버스트가 발생했을 때 저축분을 사용하다가 그럼에도 버스트가 멈추지 않자 쓰로틀이 발생하여 처리량이 급감한 것을 볼 수 있다.
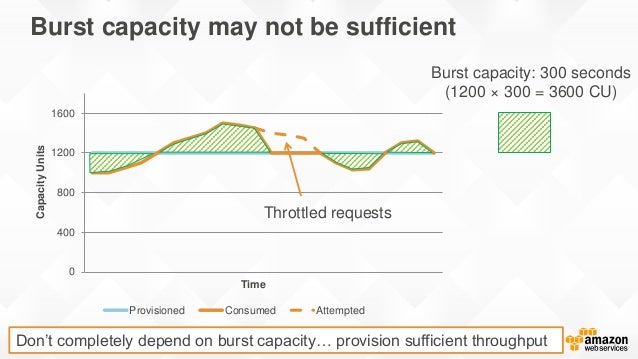
쓰로틀은 다음 이유로 발생할 수 있다.
- 어떤 파티션에 부하가 집중되는 경우
- 상상도 못한 매우 큰 버스트 ┏(ºдº)┛
후자의 경우에는 어쩔 수 없는 불가항력에 가깝다. 인기가 급상승하여 클라이언트가 갑작스럽게 많아지는 경우가 이에 해당한다. 이런 이유로 쓰로틀이 발생한다면 샴페인을 따고 기뻐하면 된다.
하지만 전자의 경우에는 상황이 다른데 핫 파티션이 결국 일을 터트린것으로 볼 수 있다. 다시 설계단계로 돌아가서 핫 파티션을 막아야 쓰로틀의 발생을 최소화할 수 있다.
관계별 조회방법
일대일 관계
해시키를 효율적으로 사용해야 한다. 단일 조회나 배치 조회가 적합하다.

일대다 관계
범위키를 효율적으로 사용해야 한다. 용량유닛을 절약하기 위해 쿼리 조회가 적합하다.
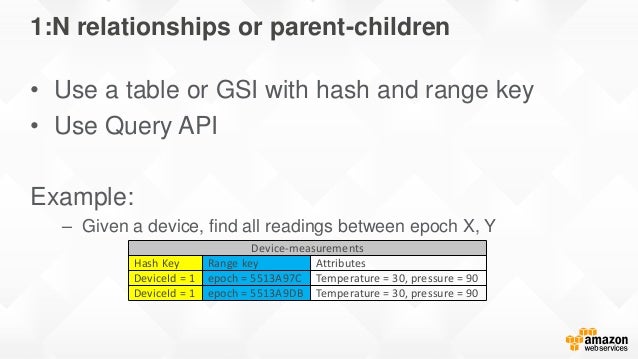
다대다 관계
범위키를 효율적으로 사용해야 한다. 그리고 자주 사용하는 속성의 조합은 GSI로 만드는 것을 고려해보자. 용량유닛을 절약하기 위해 쿼리 조회가 적합하다.

'# Tech > DynamoDB' 카테고리의 다른 글
| DynamoDB + GUI 로컬 개발환경 세팅하기 (0) | 2019.12.09 |
|---|---|
| DynamoDB 깊게 입문하기 (2) - DynamoDB Deep Dive (2) (2) | 2019.11.17 |

