개요
커서기반 페이지네이션에서 임의의 정렬조건의 순번을 계산해야 하는 상황이 있을 수 있습니다. 다음 상황을 살펴보겠습니다.

커서로는 IDX가 쓰일것이고 어떠한 항목도 필터링하지 않았을 때 순번으로도 활용할 수 있지만, X가 작성한 게시글만 보기위해 필터조건을 건다면 IDX는 더이상 순번으로 사용할 수 없습니다.
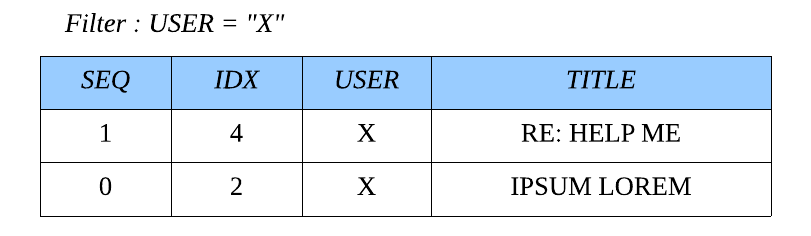
이러한 상황에서 어떻게하면 효율적으로 SEQ를 계산할 수 있을까요? 🤔
실습 데이터 생성
-- 테이블 생성
CREATE TABLE TEST (
idx int4 primary key,
userid int4,
contents text
);
-- 인덱스 생성
CREATE INDEX test_userid_idx ON TEST(userid, idx);
-- 데이터 생성
INSERT INTO TEST
SELECT
N AS idx,
N % 7 AS userid,
N::text AS contents
FROM generate_series(0, 10000000) AS N;간단하지만 느린 쿼리
쿼리문
가장 최근에 작성된 게시글부터 조회해야 하므로 idx는 역순으로 정렬하고 idx <= 500000인 항목에서 userid=3이 작성한 게시글 10개를 가져오겠습니다. 또한 userid=3 기준에서 바라본 순번은 먼저 작성된 순서대로 부여되므로 다음과 같이 작성하면 되겠군요. 마지막으로 ROW_NUMBER()은 1부터 시작하기 때문에 1을 빼겠습니다.
SELECT
ROW_NUMBER() OVER(ORDER BY idx ASC) - 1 AS seq,
*
FROM test
WHERE
idx <= 500000 AND
userid=3
ORDER BY idx DESC
LIMIT 10;실행계획
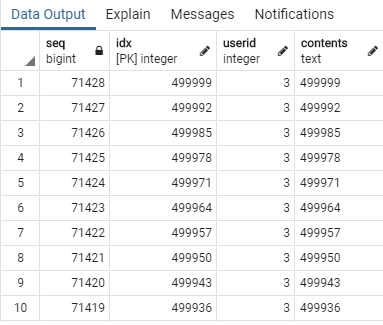
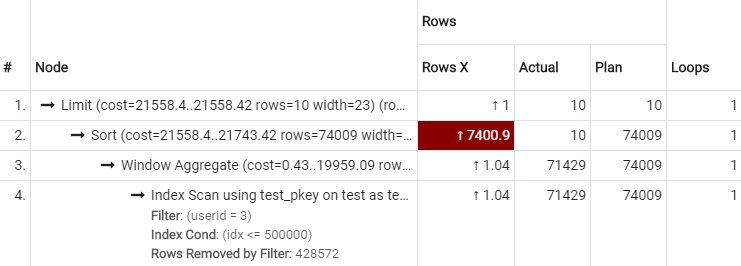
기껏 인덱스를 만들어줬지만 옵티마이저는 PK를 선택했군요... 😭 평균 실행시간은 230ms입니다.
비효율 찾기
실행계획을 살펴보면 비효율적인 곳을 쉽게 찾을 수 있습니다.
PK로 스캔하여userid=3에 해당되지 않은428572건을 읽고서도 그냥 버린 것userid=3에 해당하는71429건에 대해ROW_NUMBER()가 하나하나 순번을 붙인 것
쿼리 튜닝하기
쿼리문
키 포인트는 다음과 같습니다.
userid<=500000에 대해count(*)를 사용하여 오프셋 계산하기- 10건에 대해서만
ROW_NUMBER()을 사용하고 이것을 오프셋에 더하거나 빼기
WITH base AS (
SELECT COUNT(*) - 1 AS _offset
FROM test
WHERE
idx <= 500000 AND
userid = 3
)
SELECT
_offset - (ROW_NUMBER() OVER() -1 ) AS seq,
test.*
FROM test, base
WHERE
idx <= 500000 AND
userid = 3
ORDER BY idx DESC
LIMIT 10실행계획
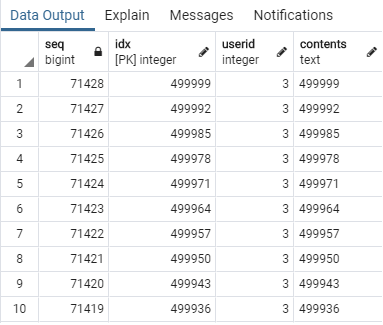

실행계획을 분석해보면 _offset을 계산하는 윗쪽과 조건에 맞는 10건을 가져오는 아랫쪽으로 나눌 수 있습니다.
먼저 아랫쪽부터 살펴볼까요? WINDOW_AGGREATE의 Acutal이 10이라는 것을 보면 ROW_NUMBER()가 최종 10건에 대해서만 적용되었다는 것을 알 수 있습니다. 아랫쪽에 의한 비용은 한없이 작다라고 해도 과언이 아니네요. 😀
윗쪽은 _offset을 계산하는 그룹이죠. count는 인덱스와 함께 사용하면 성능이 향상되는 경우가 많기 때문에 옵티마이저는 최대한 인덱스 스캔을 하려고 할겁니다. 실제로 실행계획에서 옵티마이저가 PK를 고른것을 확인할 수 있죠.
인덱스 강제하기
아직 비효율이 남아있습니다.
옵티마이저가 _offset을 계산하는데 PK를 사용한 덕분에 142857건을 읽고서도 그냥 버린것을 확인할 수 있었죠. 다시보니 아랫쪽에서도 55건 정도를 그냥 버렸네요. 이번에는 불필요한 I/O가 없어지도록 힌트를 사용하여 인덱스를 강제하겠습니다.
/*+ IndexScan(test test_userid_idx) */
WITH base AS (
SELECT COUNT(*) - 1 AS _offset
FROM test
WHERE
idx <= 500000 AND
userid = 3
)
SELECT
_offset - (ROW_NUMBER() OVER() -1 ) AS seq,
test.*
FROM
test,
base
WHERE
idx <= 500000 AND
userid = 3
ORDER BY idx DESC
LIMIT 10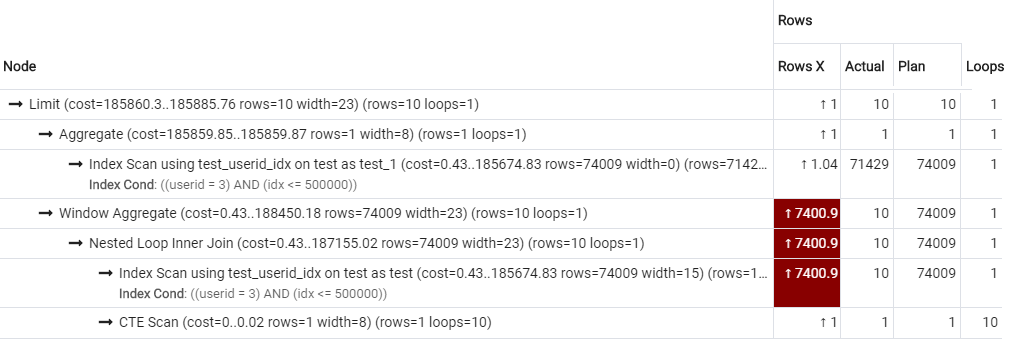
겉으로 보기에는 비용이 더 높아졌기 때문에 옵티마이저가 PK를 선택했군요. 🤔 하지만 I/O 측면에서는 test_userid_idx가 최적이기 때문에 실제로는 실행시간이 더 줄어들었을겁니다.
실제로 평균 실행시간이 130ms정도로 줄어들었고, seq를 제외하고 실행했을 때가 120ms정도였으니 튜닝이 성공적으로 이루어졌음을 알 수 있습니다.